Most VMs use stacks because that's what computer science textbooks teach. BEAM said "fuck that" and went with registers instead. This actually matters when you're running 2 million WebSocket connections and your traditional thread-pool server starts swapping to death at 3am. The register architecture eliminates all the stack manipulation bullshit that other VMs waste cycles on.
Registers vs Stack: Why It's Not Just Theory
Stack machines spend their time pushing and popping shit around. Every operation is push A, push B, add, pop result. BEAM skips this dance and treats registers like variables in your code:
X-Registers
Function arguments and temp data. When you call foo(1, 2, 3), those values land in {x,0}, {x,1}, {x,2}. Return value comes back in {x,0}. Simple. The BEAM instruction set documentation shows exactly how these registers work.
Y-Registers
Stick around across function calls. Critical for tail recursion optimization - without these, your recursive functions would blow the stack faster than you can say "fibonacci". The Erlang efficiency guide explains how BEAM optimizes these patterns.
The real difference? Instead of push 5, push 3, add, pop result, BEAM does {gc_bif,'+',{f,0},3,[{x,1},{x,0}],{x,0}}. One instruction, done. This matters when you're running 2 million processes and every CPU cycle counts. The BEAM Book has detailed analysis of why this register approach is more efficient than stack machines.
The Scheduler That Actually Works
BEAM counts reductions - basically VM operations. Hit your quota? Your process gets kicked off the CPU, no questions asked. This used to be a fixed 2000 in older OTP versions, but now it's adaptive based on workload. I've seen this bite people who upgraded from OTP 23 to 25 and suddenly their tight loops started behaving differently. Spent a week debugging why our image processing pipeline slowed down 30% after what seemed like a routine OTP upgrade - turns out the reduction counting changes affected our CPU-bound image transforms.
This isn't time-slicing where some dickhead process can hog the CPU between timer interrupts. This is operation-counting. Your infinite loop gets exactly 2000 reductions (well, around 2000 - it varies), same as a well-behaved HTTP handler. The scheduler doesn't give a shit what your code thinks it's doing - learned this debugging an infinite loop that was mysteriously not blocking other processes, which confused the hell out of me until I understood reduction counting.
%% This will get preempted every ~2000 reductions
%% preventing it from fucking over other processes
busy_loop(0) -> done;
busy_loop(N) -> busy_loop(N-1).
One scheduler thread per CPU core. Each handles millions of BEAM processes. Context switch between BEAM processes? Around 2.6KB. OS thread context switch? 8-16KB plus all the kernel overhead bullshit. You do the math. WhatsApp handled 450 million users with 32 engineers - this efficiency is why, though let's be honest, they also had some brilliant engineers and probably more luck than they'll admit.

Per-Process GC: No More Stop-The-World Bullshit
The JVM stops everything for garbage collection. Your web server freezes. Your real-time chat app hiccups. Your monitoring dashboard shows lovely spikes every few seconds and users start complaining. BEAM said "that's fucking stupid" and gave each process its own garbage collector.
Process needs memory cleanup? Only that process pauses. The GC counts as reductions, so it gets scheduled like any other work. I've seen BEAM systems run for months without a single global pause. Try that with the JVM.
This works because BEAM processes can't share mutable state. Everything is immutable. No shared references between processes means the GC only needs to look at one process's heap. Simple, predictable, and it actually works when you're getting paged at 2am. Java's G1 collector still stops the world occasionally even with all its fancy algorithms.
Message Passing: The Good and The Ugly
Messages get copied between process heaps. No shared memory, no locks, no race conditions. Sounds great until you try to send a 100MB binary between processes and watch your memory usage double.
%% This copies the entire message to the recipient's heap
%% Hope it's not a huge data structure
Pid ! {data, "Hello World"},
receive
{data, Message} -> io:format("~s~n", [Message])
end.
The receive mechanism pattern matches at the VM level. It scans your mailbox until it finds a match, leaving everything else for later. This is where BEAM can bite you hard - a process with 50,000 unmatched messages in its mailbox will scan all 50,000 messages every time you try to receive. I've debugged systems where one process with a massive mailbox brought down entire nodes during peak traffic.
But when it works, it really works. Process crashes? Everything else keeps running. The crashed process's memory gets cleaned up, mailbox gets flushed, and supervisors restart it in milliseconds. I've seen production systems lose individual processes and keep serving traffic like nothing happened. Discord does this at massive scale - millions of concurrent voice connections that keep working even when individual processes die. Though to be fair, when BEAM itself crashes, you're still fucked.
Why 1980s Telecom Tech Still Matters
BEAM was designed for telecom switches that couldn't go down. Ever. Not for web apps, not for microservices, not for blockchain bullshit. For systems where downtime meant people couldn't call 911.
Teams that build on BEAM learn to design around failure. The platform assumes things will break, and when they do, everything else keeps working. WhatsApp famously built their entire platform this way - designed for components to fail gracefully while the system stayed up.
The register-based design eliminates stack overhead. Reduction-based scheduling prevents process starvation. Per-process GC eliminates global pauses. Message passing isolates failures. These aren't separate features - they're a complete system designed around one principle: keep the lights on.
Is BEAM perfect? Fuck no. The tooling can be frustrating, the learning curve is steep, and some things (like floating-point math) are painfully slow. But when you need a system that stays up during Black Friday traffic, handles concurrency without deadlocks, and degrades gracefully when everything goes to shit, BEAM delivers. I learned this the hard way after years of fighting thread pools and connection limits on traditional platforms. Been running BEAM in production since OTP 17 - watched it evolve from quirky telecom tech to something you can actually build modern systems on without losing your mind.
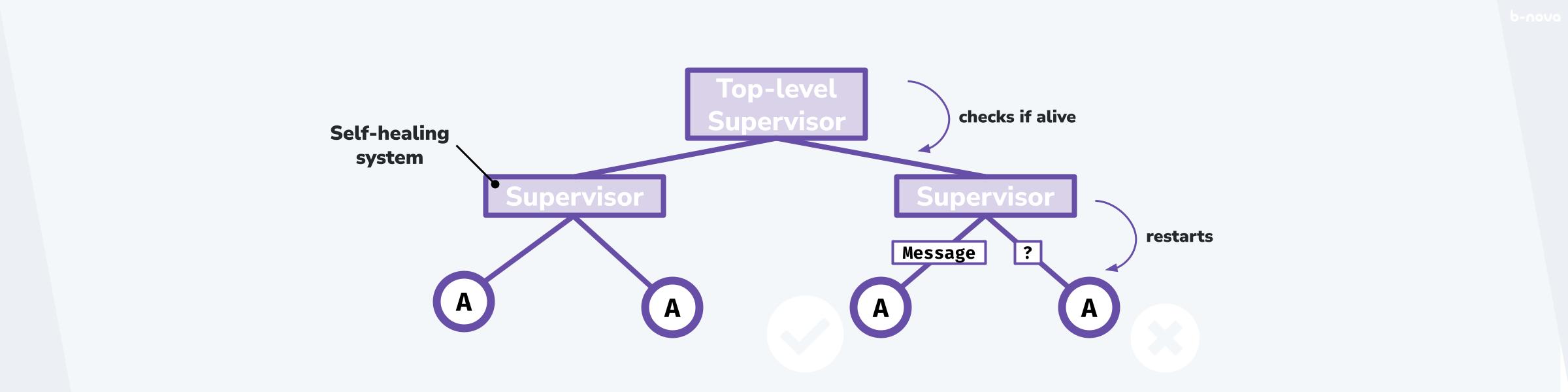
The diagram above shows how BEAM's supervisor tree architecture works in practice - when one process fails, only that branch of the tree needs to restart, keeping everything else running.