If you've been managing Kubernetes clusters for more than five minutes, you know the pain. YAML files scattered everywhere, half your clusters running different versions of everything, and every update becomes a three-day project involving seventeen different tools that may or may not play nice together.
Spectro Cloud Palette is basically what happens when someone said "fuck this, there has to be a better way" and actually built it. Instead of managing OS patches separately from K8s updates separately from networking separately from storage separately from monitoring separately from... you get the idea.
The thing that actually makes sense
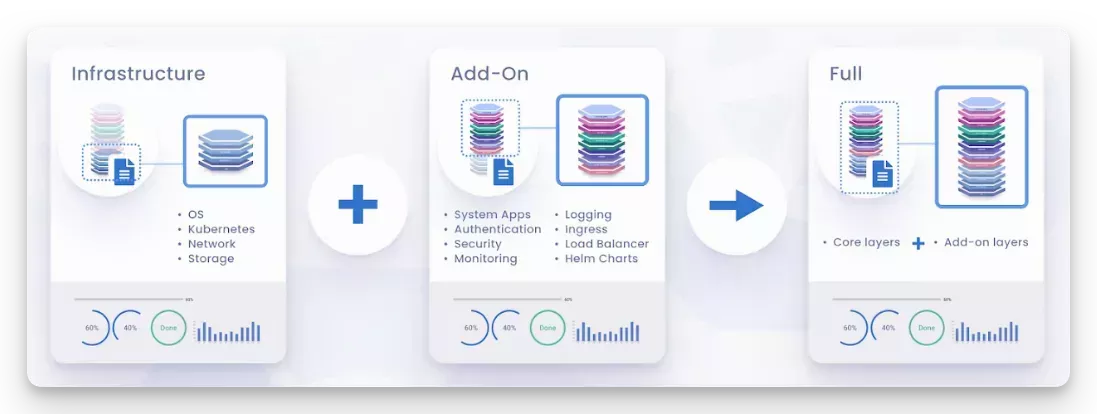
Palette uses this concept called Cluster Profiles which is basically infrastructure-as-code but for your entire K8s stack. Think Terraform but for Kubernetes clusters, not just infrastructure. The GitOps workflow concept applies to everything from OS patches to application deployments. You define everything from the OS up to your applications in one place, version it, and deploy it consistently everywhere. No more "it works on my machine" bullshit when cluster A has Ubuntu 20.04 and cluster B has RHEL 8.
Here's what broke when I tried this the hard way: 30 clusters across AWS and on-prem, each one a beautiful snowflake. When CVE-2024-3727 dropped (that container registry vulnerability that hit image scanning), it took three weeks to figure out which clusters were vulnerable because we had no fucking clue what was running where.
With Palette, you know exactly what's on every cluster because it's all defined in your profiles. When that CVE hit, I knew in 10 minutes which clusters needed patching and pushed the fix in an hour.
Who's actually using this
The usual suspects are on board - GE Healthcare, T-Mobile, U.S. Air Force. But what's interesting is these aren't just logo placements. GE Healthcare is running medical devices on Palette-managed edge clusters. The Air Force is using it for classified workloads. T-Mobile is managing their 5G infrastructure with it.
That tells you something - this isn't just another dashboard for kubectl. These orgs are betting critical infrastructure on it.

Why it's different from the alternatives
Full-Stack Management: While Rancher gives you a nice UI and OpenShift gives you a platform, Palette actually manages everything from kernel patches to application updates. Unlike Platform9 or Docker Swarm, you're not managing a dozen different tools. I don't have to use separate tools for OS management and K8s management - it's all one thing.
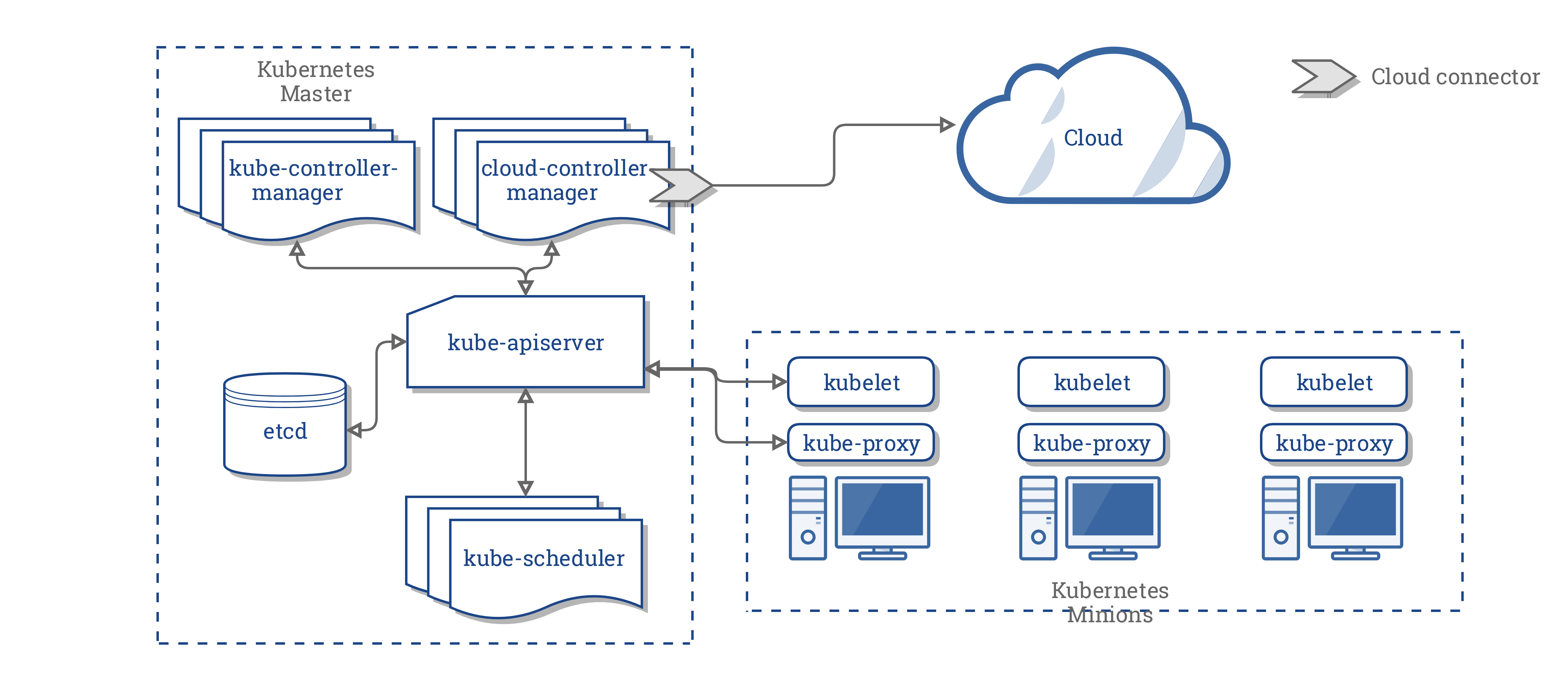
Works when shit goes wrong: The decentralized architecture means when your management plane goes down (and it will), your clusters keep running according to their profiles. I've seen too many centralized systems where one controller failure takes down visibility to everything.
Actually supports edge: Most platforms say they support edge but really mean "3-node clusters in a different AZ." Palette actually works with 2-node HA setups on ARM devices in places where network connectivity comes and goes. I've deployed clusters on NVIDIA Jetson devices that only sync up once a day.

The State of Production Kubernetes 2025 report confirms what we all know - K8s complexity is getting worse, not better. CNCF surveys show the same trend, and Stack Overflow's developer survey shows K8s remains one of the most feared technologies. Palette is one of the few tools that actually makes it simpler instead of adding another layer of complexity.