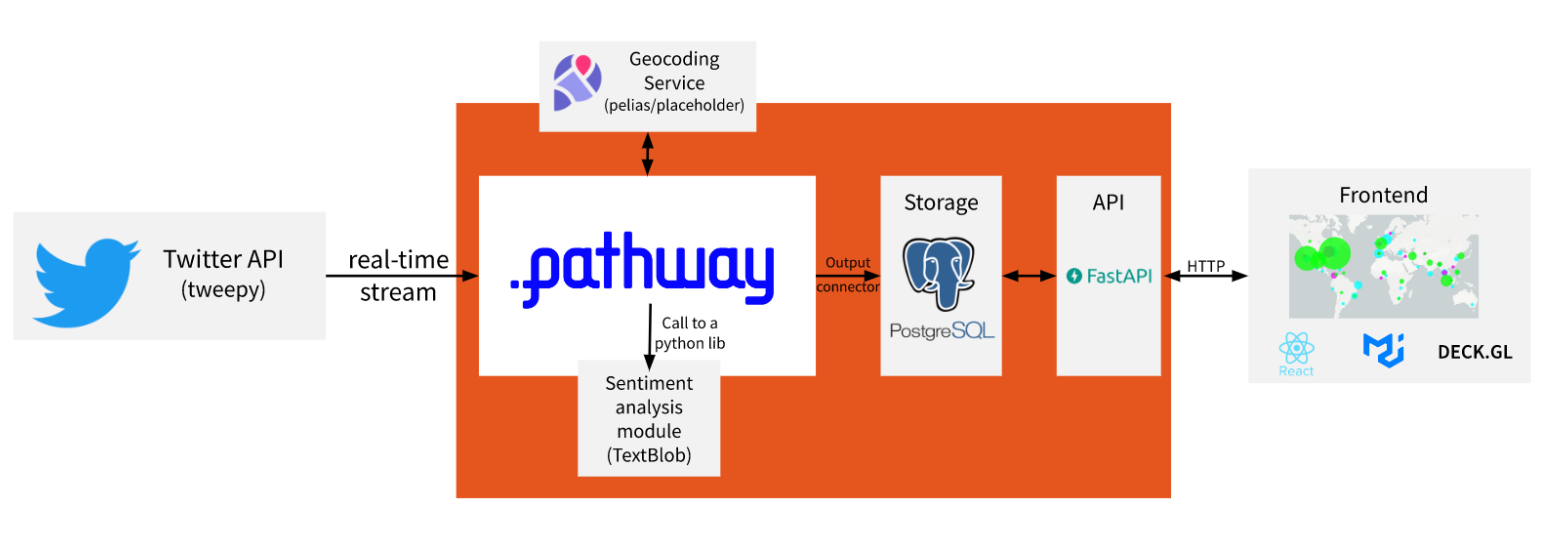
Most data teams maintain separate batch and streaming codebases because that's what Spark and Flink force you to do. This is expensive as hell - we learned that after months of maintaining two codebases where Spark batch jobs worked fine but Flink kept shitting the bed in production. Never figured out the root cause, just switched frameworks.
Pathway (~42k GitHub stars) was built by researchers who got tired of this dance. Same Python code, different execution modes - batch for historical data, streaming for live updates. No more translating logic between frameworks and wondering why performance characteristics change.
The Architecture Actually Makes Sense
Pathway is built on Differential Dataflow, which is fancy talk for "only recompute what changed." When new data arrives, it doesn't reprocess everything from scratch like Spark does. The Rust engine handles the messy bits - threading, memory management, distributed computation - while you write normal Python.
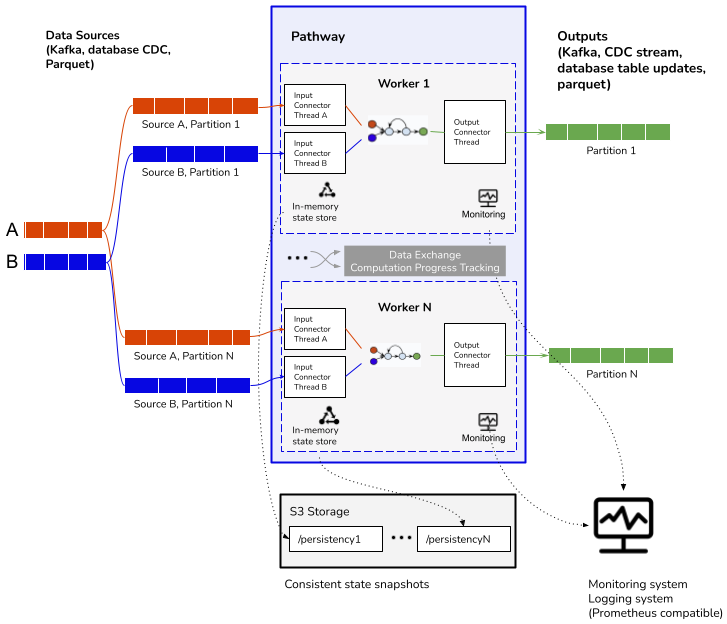

This matters because most data engineering teams waste months maintaining separate dev/test/prod environments. Your local Jupyter notebook uses Pandas, your CI tests run batch Spark, and production runs Kafka Streams. Three different mental models, three different failure modes. Pathway lets you test locally on CSV files, then deploy the same code to production Kafka - no translation layer bullshit.
The multi-worker deployment is based on that Microsoft Naiad paper everyone cites but nobody reads, which means it's built on actual computer science rather than hacked-together startup code. Each worker runs the same dataflow on different data shards, communicates via shared memory or sockets, and tracks progress efficiently.
The Stuff That Actually Matters
Pathway automatically manages late-arriving data and out-of-order events, which is something you'll appreciate when your Kafka producer decides to shit the bed during dinner. The free version gives you "at least once" processing (good enough for most use cases), while enterprise gets you "exactly once" if you're paranoid about duplicate processing.
Latest version (0.26.1) requires Python 3.10+ and runs on macOS/Linux. Windows users need Docker or WSL - learned this when our Windows intern spent a whole day trying to get it running natively.
The BSL 1.1 license is basically "free for everything except building a competing hosted service." Code auto-converts to Apache 2.0 after four years, so no vendor lock-in concerns. Way better than dealing with Confluent's license drama or Oracle's lawyers.
So how does this compare to what you're already using?