Look, Clair does one thing really well: it scans your container images for known vulnerabilities before they hit production. That's it. No runtime monitoring, no behavioral analysis - just static analysis of what packages are sitting in your Docker layers.
The beauty is in its simplicity. You throw a container manifest at Clair's API, it downloads your image layers (yes, all of them), figures out what packages you've got installed, and matches them against every CVE database it knows about. Then it tells you which ones are fucked.
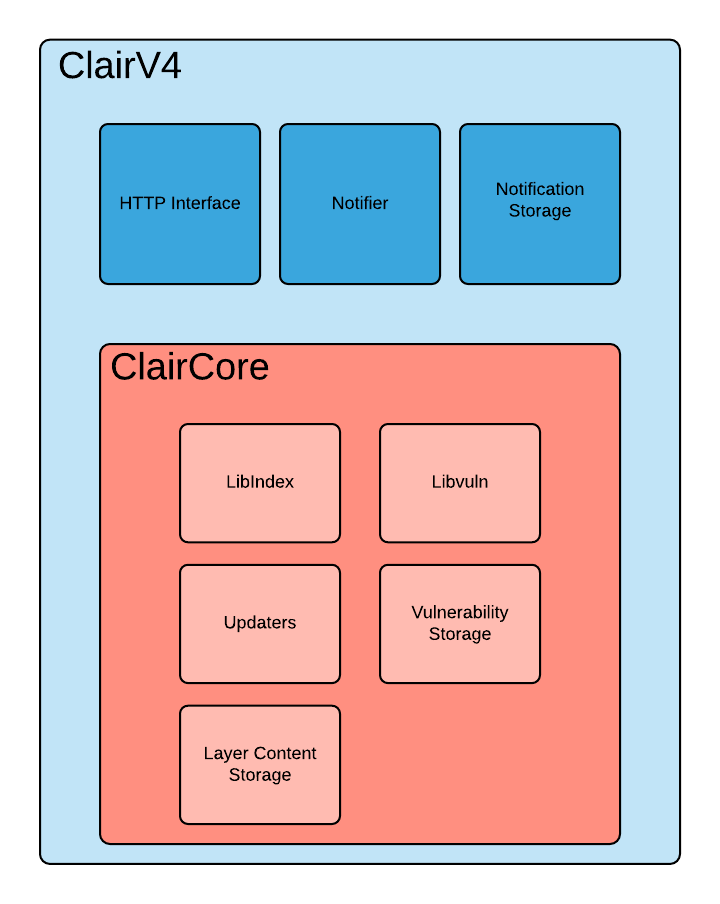

The Three-Phase Dance That'll Save Your Ass
Indexing is where Clair downloads your entire image and tears it apart layer by layer like a forensic autopsy. This is when you'll first notice your network bandwidth getting absolutely hammered - I clocked a 2GB ML container with 47 layers taking anywhere from 3 minutes to "holy shit it's been 20 minutes" depending on whether Docker Hub is having one of its mood swings.
Anyway, here's how this actually works - ClairCore (the actual scanning engine) rips through every damn layer and catalogs every package, Python wheel, and that weird shell script you definitely copy-pasted from StackOverflow.
Here's the kicker: Clair is smart about layer deduplication. If you're using the same base Ubuntu image (I think we were on 20.04, can't remember exactly) across 200 containers, it only downloads and scans those base layers once. This is why teams that standardize on base images see massive performance improvements - like, actually fast scan times instead of waiting around for minutes.
Matching happens every time you ask for a vulnerability report. This is the genius part: instead of storing vulnerability data with each scan, Clair keeps live vulnerability databases that update continuously. So when that new OpenSSL vulnerability drops at 2am, you don't need to rescan everything - just re-query the matcher and it'll tell you which of your 400 images are affected.
Notifications are where most people completely lose their shit trying to get webhooks working. You can set up webhooks to ping your Slack channel when new vulnerabilities hit your images, but I guarantee you'll spend at least 2 hours debugging why your JSON parsing keeps failing because the notification payload format is about as intuitive as assembly language.
What Clair Actually Supports (2025 Reality Check)
Linux distros that won't make you cry:
- Ubuntu (most tested, fewest surprises)
- Debian (rock solid, boring in the best way)
- RHEL/CentOS (if you're into that Enterprise Life)
- Alpine (tiny but complete coverage)
- Amazon Linux (because AWS)
Language ecosystems where Clair won't let you down:
- Python packages via pip/requirements.txt analysis (solid since day one)
- Go modules and dependencies (ClairCore v4.8+ - finally works right)
- Java JARs and Maven dependencies (spotty but improving)
- OS packages via apt, yum, apk package managers (this is where it shines)
What it still sucks at: JavaScript/Node.js dependencies are a mess, Ruby gems are hit-or-miss, and don't even think about that random shell script you downloaded from GitHub. For comprehensive language coverage, you still need Trivy or Grype to pick up the pieces.
Performance Reality: It's Fast Until It Isn't
Those fast scan times Red Hat loves to brag about? That's for a basic Ubuntu container with maybe 200 packages. Try scanning a fucking TensorFlow image with CUDA libraries and you're looking at anywhere from 2-3 minutes on a good day to "I'll come back after lunch" on a bad one - assuming your network doesn't completely shit itself trying to pull whatever crazy amount of image data these ML people think is reasonable.
I've seen Clair supposedly handle millions of images on Quay.io, but that's with dedicated PostgreSQL clusters, Redis caching, and probably more AWS credits than your entire engineering budget for the next decade. In the real world, plan for maybe one Clair instance per 10,000 images if you want sub-minute scan times, and even then you'll probably end up disappointed.
The real performance killer is vulnerability database updates, and this is where everything goes to hell. When Ubuntu releases their daily security updates, every matcher instance needs to rebuild its correlation data. This can lock up scanning for anywhere from 5 minutes to "holy shit it's been half an hour and nothing's working" during peak hours. There's no good way to predict when this will happen or how long it'll take.
