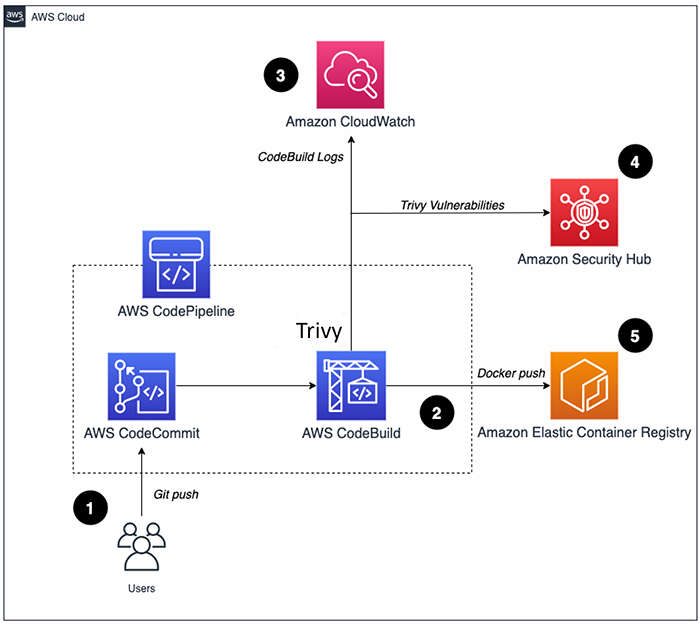
Anchore Engine died in January 2023 after years of being a pain in the ass to maintain. Not because it was a bad idea - actually the opposite. Anchore learned from Engine's nightmare architecture and built something way better: Syft for SBOM generation and Grype for vulnerability scanning that actually works.
The official migration guide provides detailed transition steps, while the Anchore Engine GitHub repository contains the final migration recommendations from the development team.
The Architecture That Led to Deprecation
Engine was a monolithic piece of shit that needed PostgreSQL, multiple containers, and way too much infrastructure. It worked sometimes but had fatal flaws:
Resource Heavy: Engine ate PostgreSQL for breakfast and shit out OOM errors. "Basic" deployment my ass - it needed 4GB RAM minimum and routinely demanded more during scans. The deployment guide was like reading War and Peace, except more depressing.
Complex as Hell: Managing catalogs, policy engines, analyzers, and API servers that all failed in their own special ways. Each service had its own config files, scaling quirks, and creative ways to break at 3am. The architecture docs read like a Rube Goldberg machine manual, and the troubleshooting guides were longer than most novels.
Slow as Molasses: Want to add a new package manager? Good luck coordinating changes across five different services that hate each other. Development moved at the speed of bureaucracy. The community forums were basically a support group for people dealing with Engine's architectural sins.
CI/CD Nightmare: Sure, it had REST APIs, but integrating them was like performing surgery with a chainsaw. Startup times alone could kill your build pipeline. The CI/CD integrations needed more config than a Space Shuttle launch.
The Modern Replacement: Syft + Grype
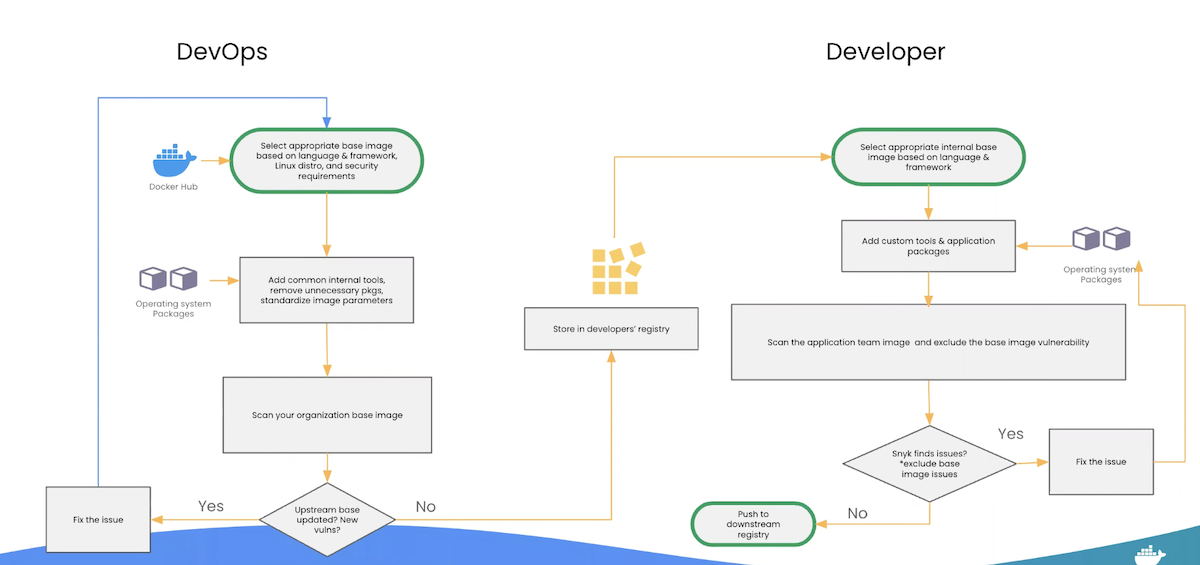

Instead of that monolithic monster, Anchore split the functionality into two tools that actually work:
Syft generates SBOMs from container images without being a prima donna about it. Fast, lightweight, and supports CycloneDX and SPDX formats that actually work with other tools. Handles 25+ package ecosystems and private registries without throwing a fit.
Grype scans for vulnerabilities and doesn't suck at it. Takes SBOMs from Syft or scans images directly. Works with multiple output formats, custom templates, and has GitHub Actions that won't break your workflows.
Splitting the tools fixed all the shit everyone hated about Engine:
- Actually fast scans: Grype finishes in minutes instead of the hour+ clusterfuck Engine put you through
- No more database babysitting: Zero PostgreSQL maintenance, corruption nightmares, or memory leaks
- CI/CD that doesn't suck: No waiting for services to start or random API timeouts ruining your day
- Deploy and forget: Install two binaries and you're done - no Docker Compose hell
- Development that moves: Adding package managers doesn't require coordinating 5 services that hate each other
What You Lose in Migration
Look, before you get all excited about migrating, here's what Engine had that the CLI tools don't (spoiler: you probably don't need most of it):
Web UI and Dashboard: Engine's web UI was garbage anyway - half the links were broken and it crashed regularly under load. Most teams ended up building Grafana dashboards because the built-in UI was so unreliable.
Centralized Policy Management: Engine's policy system was powerful in theory, nightmare to maintain in practice. Complex JSON policies that nobody understood, and debugging policy failures meant digging through PostgreSQL logs. Most organizations only used basic severity thresholds anyway.
User Management and RBAC: Engine's RBAC was overkill for most use cases. Teams spent weeks configuring permissions that could be handled with proper CI/CD access controls. The CLI tools integrate with whatever auth system you already have.
Persistent Scan History: Engine hoarded everything in PostgreSQL like a digital pack rat. Constant vacuum operations, regular corruption, and "historical data" that was mostly digital garbage. Once you implement continuous scanning that actually works, you won't miss those old scan results collecting dust.
Repository Watch Lists: Engine's registry monitoring was like a drunk security guard - worked when it felt like it. Random failures, missed images, cryptic error messages. A cron job is more reliable than this piece of shit feature ever was.
What You Gain in Migration
Performance: Our Engine deployment was a nightmare - 15-20 minutes scanning a Node.js app when it didn't completely shit the bed. Grype does the same thing in under 2 minutes. Engine OOM-killed itself constantly, didn't matter how much RAM we threw at the bastard.
Reliability: No more 3am pages because PostgreSQL corrupted again and I had to rebuild from backups like some kind of digital archaeologist. No more "analysis stuck" mysteries that required nuking the entire service cluster. Each scan is isolated - fails fast with actual error messages instead of cryptic database voodoo.
Maintenance: Went from weekly PostgreSQL maintenance windows (because it always broke) to zero maintenance. No monitoring 5+ services that hated each other, no log rotation eating our disk, no "catalog service disconnected" errors at random times.
Integration: Engine's API was bipolar - worked fine then randomly threw 500 errors under load. CLI tools are boring in the best way - exit code 0 means success, anything else means it failed. No polling APIs waiting for "analysis_status": "analyzed" like some kind of masochist.
SBOM Standards: Syft's SBOMs work with every scanner we've tested. Engine's custom format only worked with Engine because of course it did. Want to try a different vulnerability scanner? Feed it the same SBOM instead of being locked into Anchore's ecosystem.
Migration Strategy: Don't Make Our Mistakes
Most teams try to rebuild Engine's exact functionality with the CLI tools. Don't make our mistake - you'll end up with something more fucked up than the original.
What We Did Wrong: Wasted three months building databases to store scan results, a shitty web UI nobody used, and orchestration to recreate Engine's service mesh of doom. The result was more complex than Engine and broke twice as often.
What Actually Works: Use the CLI tools where they don't suck - CI/CD pipelines and automation. Your existing monitoring can handle alerts, your existing databases can handle persistence if you really need it.
Skip the gradual migration bullshit. We tried running both systems for "safety" and it was a complete nightmare. Rip the bandaid off and switch to CLI tools. You'll realize you never needed 80% of Engine's "features" once you have tools that just fucking work.
Alright, enough bitching. Here's the technical breakdown so you can plan your escape from Engine hell: