![]()
After debugging vector database performance disasters across dozens of production deployments, I've learned that traditional benchmarks are worse than useless - they're actively fucking misleading. The gap between benchmark promises and production reality has cost companies millions in infrastructure overruns and "urgent" Saturday migrations that ruin your weekend.
Academic Benchmarks Are Living in 2009
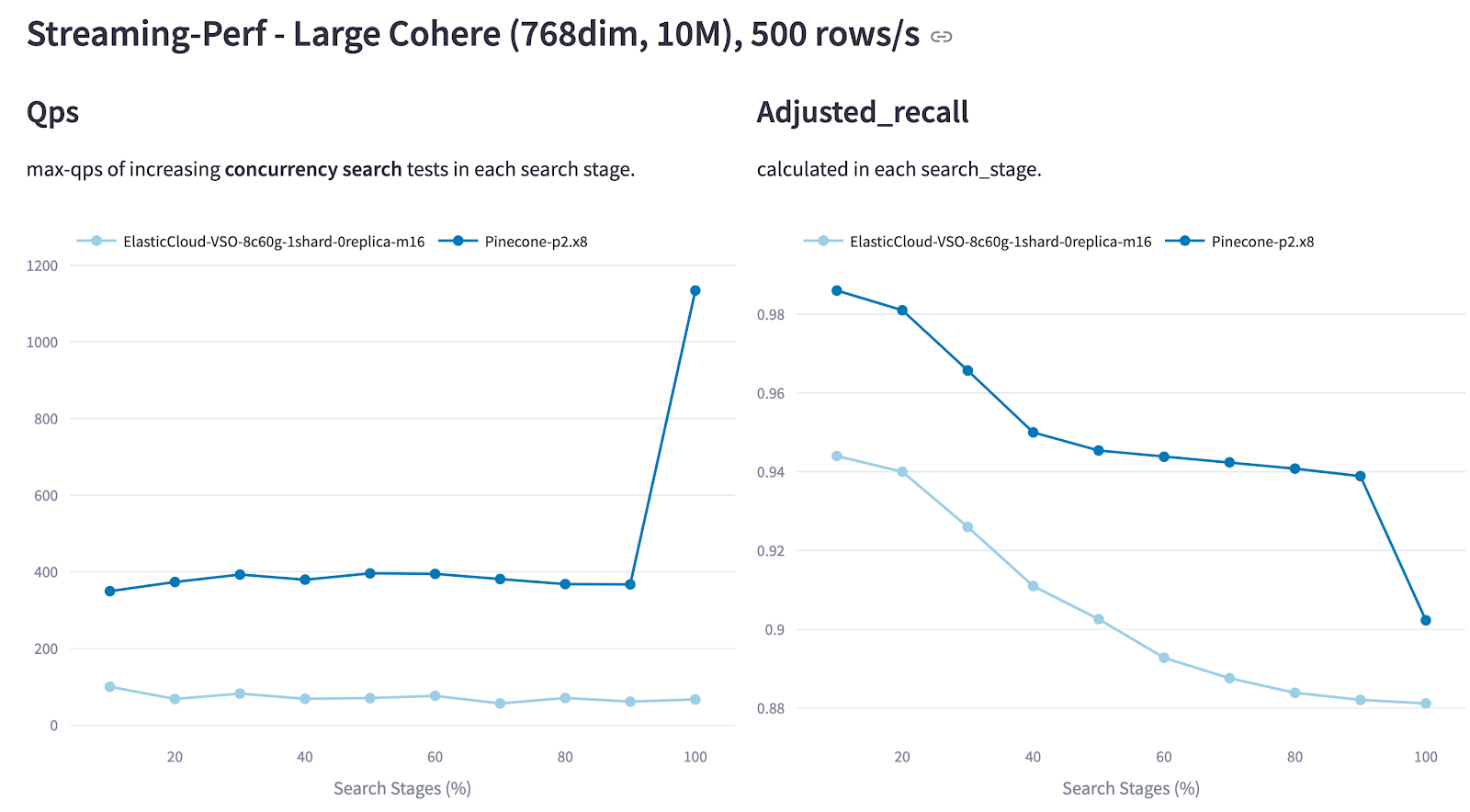
ANN-Benchmarks dominates vendor slide decks, but it tests scenarios that stopped being relevant when Obama was president. These benchmarks use 128-dimension SIFT vectors on static datasets with single-threaded queries. Real applications use 1,536-dimension embeddings with concurrent users hammering your API while data streams in continuously.
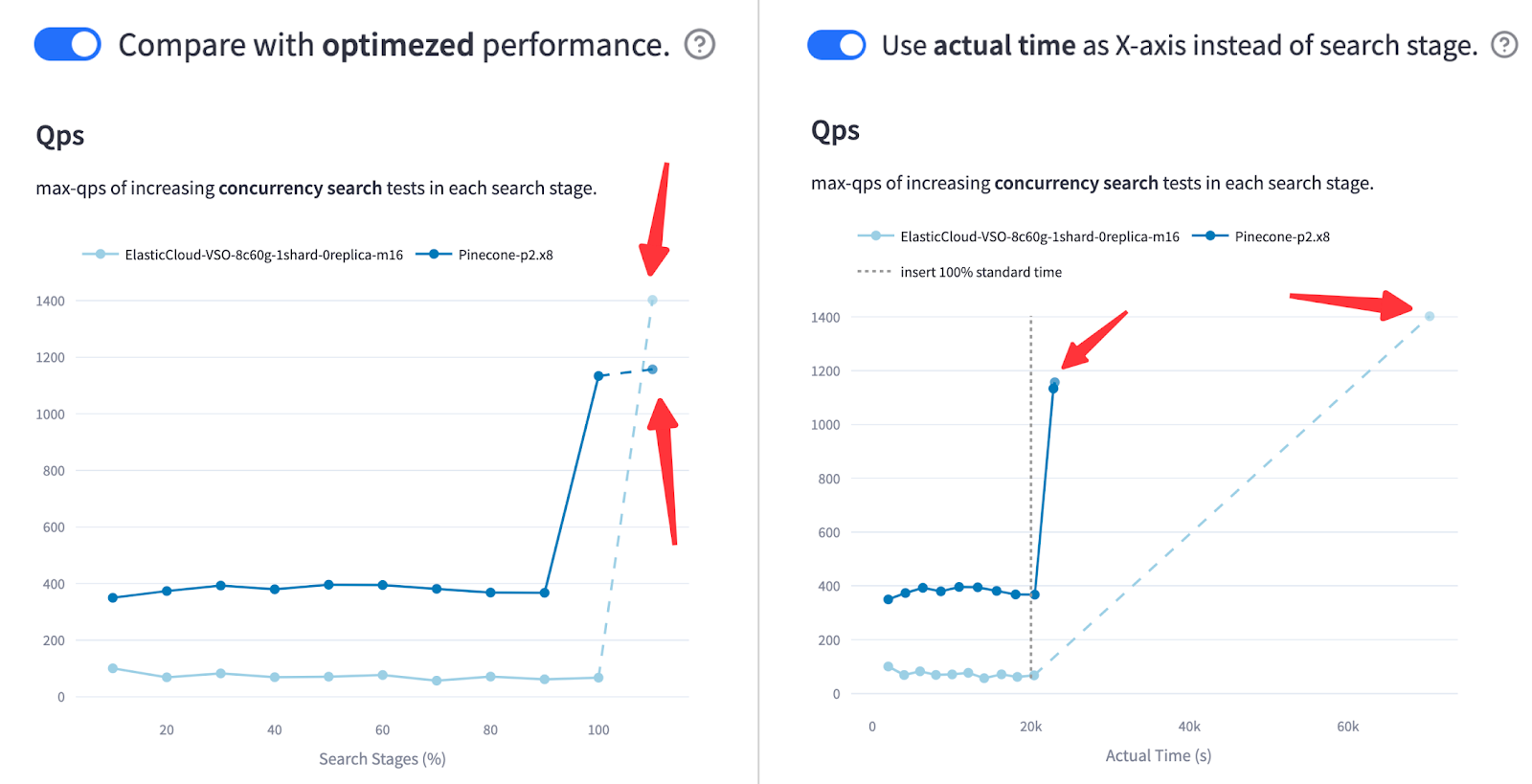
VDBBench 1.0 finally dropped in July and addresses this disconnect by testing streaming ingestion scenarios, filtered search, and P99 latency measurements that actually matter. Results showed that databases ranking first in ANN-Benchmarks often performed worst under production-like conditions.
What Actually Kills Performance in Production
Concurrent Write Operations: Most benchmarks test static data, but production systems continuously ingest new vectors. Elasticsearch requires 18+ hours for index optimization during which search performance degrades by 90%. Vendors conveniently forget to mention this bullshit in their 50ms query time marketing slides.
Metadata Filtering Nightmare: Production queries aren't just similarity searches—they're "find similar documents from this user's private data published after 2024 within this price range." Qdrant's filtered search benchmarks reveal that highly selective filters cause 10x latency spikes that will ruin your day.
Memory Access Hell: High-dimensional vectors create completely different memory bottlenecks than academic datasets. Systems optimized for 128D vectors often become memory-bound with 1,536D embeddings, causing thrashing and unpredictable performance cliffs that make you question your life choices.
Multi-tenancy Chaos: Enterprise deployments serve multiple customers simultaneously. Vector databases often lack proper isolation, causing neighbor noise where one tenant's heavy queries degrade performance for everyone else.
The Cost of Getting It Wrong
One startup I worked with picked ChromaDB because it topped some bullshit benchmark. Their AWS bill went from $800/month to $4,200/month in three weeks. Turns out Python memory management plus high-dimensional vectors equals financial disaster. They're now paying 5x what they budgeted just to keep their search barely functional.
This financial services company picked their database based on ANN-Benchmarks and got completely fucked during the first market volatility spike. Risk calculations that should've taken 50ms were timing out at 30 seconds. Migration to pgvector took 6 months and two nervous breakdowns, but their infrastructure costs dropped from $15K to $3K per month.
Anyway, here's what's actually improving for 2025:
Hardware-Optimized Indexes: NVIDIA TensorRT optimization and Triton dynamic batching are becoming standard for production deployments. Systems like Pinecone's inference endpoints combine embedding generation and search in unified hardware-optimized pipelines.
Memory Optimization Breakthroughs: Milvus 2.6 dramatically reduces memory usage without destroying recall accuracy. But watch the fuck out - the upgrade from 2.5 broke a bunch of configurations, so test it thoroughly before production. I spent 6 hours debugging segment loading failed: no growing segment found errors after upgrading because I didn't read the fine print. Product quantization techniques enable scaling to billions of vectors with way less RAM, though you'll need to retune your indexes.
Edge Computing Integration: Vector databases are moving closer to data sources. Edge-deployed vector search can reduce data processing times by up to 90% for real-time applications like autonomous vehicles and IoT systems.
Hybrid Architecture Patterns: Companies are adopting multi-vector strategies where different databases handle different workloads—Pinecone for development iteration, pgvector for production cost control, and specialized systems for specific use cases. Recent comparative analysis shows that multi-database architectures can reduce total infrastructure costs by 40% while improving performance.
Look, just test your actual workload. The databases that win academic benchmarks usually become disasters when real users hit your system.