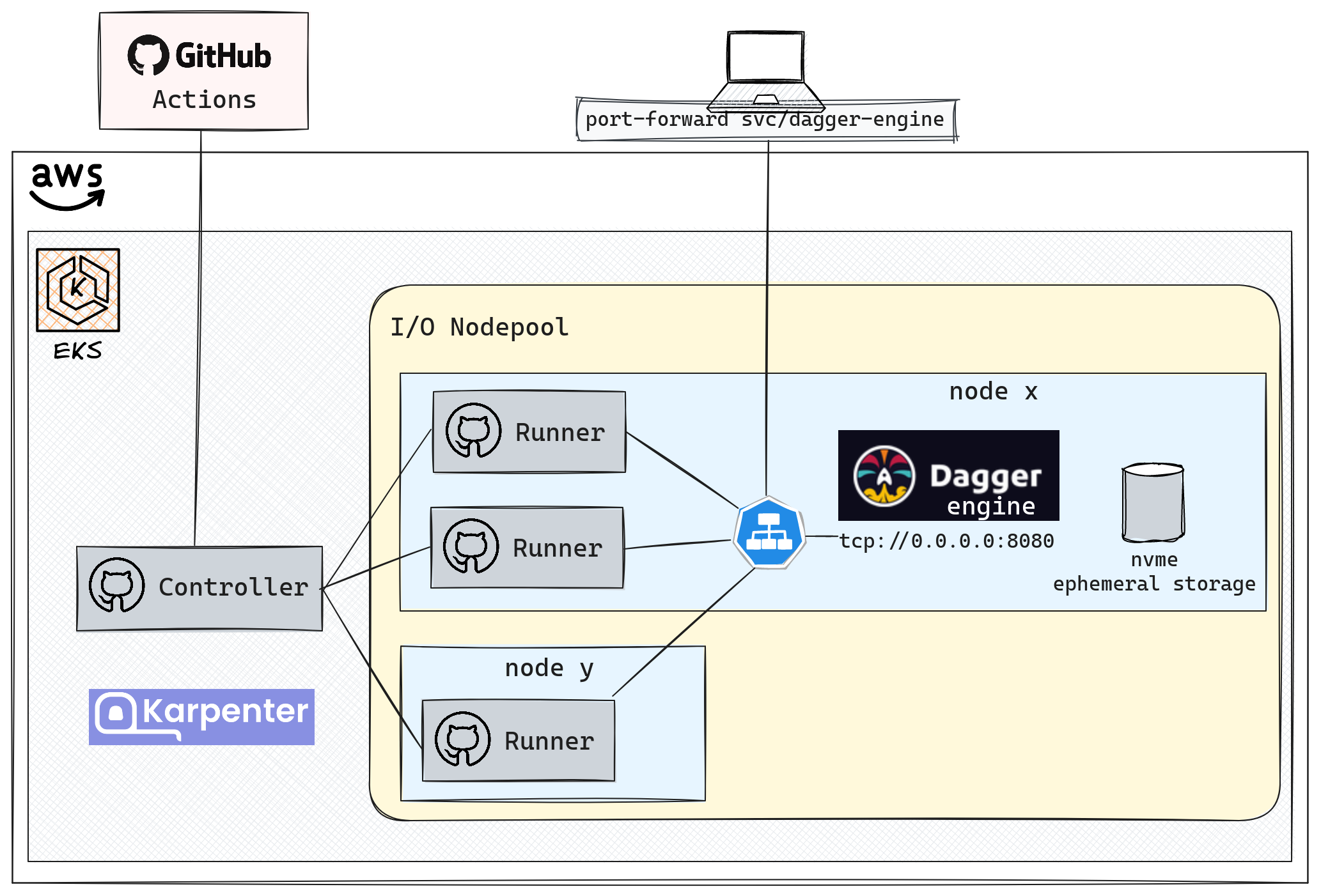
Before you jump on the Dagger bandwagon, let's talk about what you're actually getting into. Dagger isn't just a CLI tool you install and use. It's a client-server architecture where the Dagger Engine runs as a persistent daemon that manages all your builds. On my MacBook Pro M1, this daemon consistently eats 3-4GB of RAM even when idle. Nobody mentions this in the getting started guides.

The installation process looks straightforward, but here's what actually breaks: Docker Desktop needs to be running, BuildKit needs to be enabled, and if you're on Windows with WSL2, prepare for permission hell. I spent 4 hours on Windows debugging why dagger version kept returning Error: engine start timeout even though Docker was running fine. The issue? Docker Desktop WSL2 integration wasn't properly sharing the Docker socket with Dagger, and the error message was completely useless.
The Go SDK Experience
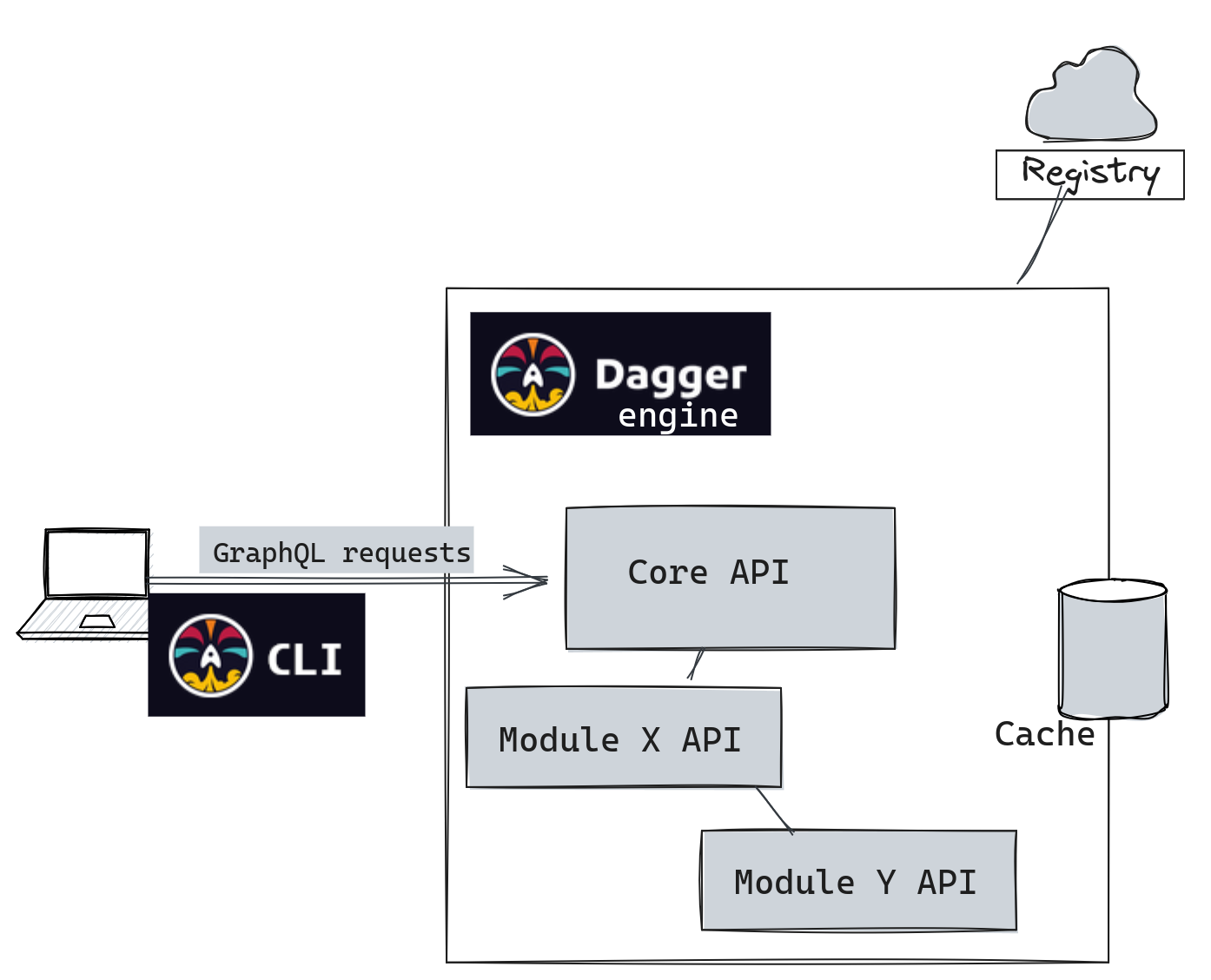
I tested primarily with the Go SDK since that's supposedly the most mature. The fluent API looks clean in examples:
func (m *MyModule) BuildApp(source *dagger.Directory) *dagger.Container {
return dag.Container().
From("golang:1.22-alpine").
WithMountedDirectory("/src", source).
WithWorkdir("/src").
WithExec([]string{"go", "build", "-o", "app", "."})
}
Reality check: this simple build took 8 minutes the first time because Dagger pulls every damn image layer through its own registry cache. The BuildKit caching is powerful once it's warmed up, but cold starts are brutal. Your first few runs will be slower than your existing setup.
What Actually Works Well
The debugging experience is genuinely better. When your build fails, you can run dagger call build-app --source=. terminal and get dropped into the exact container where the failure happened. This is documented but the real value is debugging complex dependency issues. I found three separate problems in our Node.js build that were hidden by the GitHub Actions runner environment.
The local/remote parity thing isn't marketing bullshit - it actually works. Same container, same filesystem state, same environment variables. When something fails locally, it fails the exact same way in CI. This eliminated about 80% of the "works on my machine" incidents we were seeing. The container-first approach means your development environment matches production exactly.
The Ecosystem Reality
The Daggerverse has maybe 100 modules total, and half of them look like weekend projects that haven't been updated since 2023. Compare that to the thousands of GitHub Actions or Jenkins plugins available. Want to deploy to AWS? You're writing your own module. Need Kubernetes integration? Hope you like writing CUE configuration files and debugging YAML hell in a different language.
Most modules are one-person side projects with spotty maintenance. The official modules are solid but limited. If you're doing anything beyond basic build/test/deploy workflows, you'll be implementing it yourself.
Module development means writing functions in Go, Python, or TypeScript and exposing them as pipeline steps. Each module is supposedly reusable across projects, but the ecosystem is tiny compared to mature CI/CD platforms.