
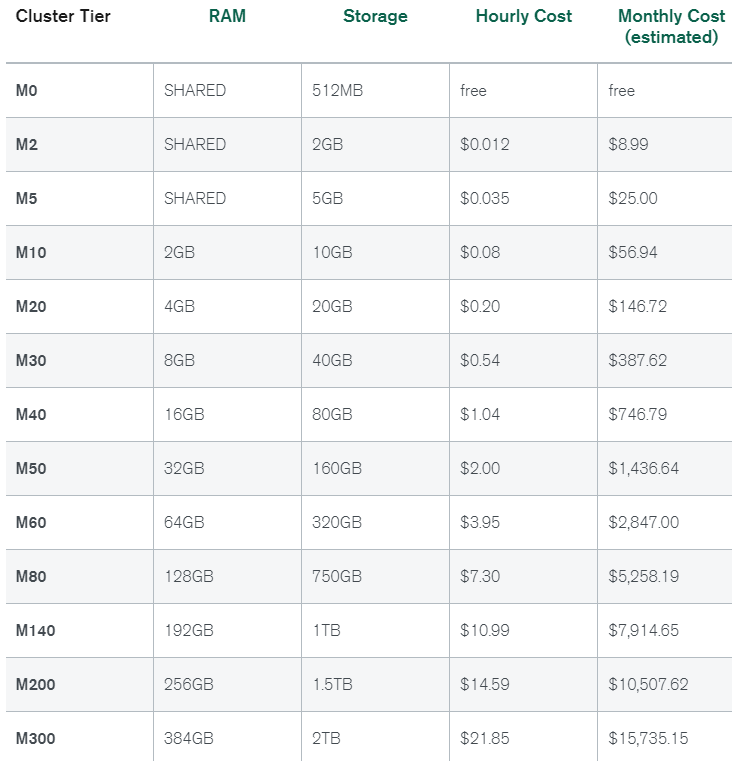
MongoDB's pricing page makes M10 at $58/month look reasonable. Biggest fucking trap in cloud computing.
Deployed an API on M10 because we only had like 3GB of data. Worked fine for a few days until we hit real traffic. Response times went to shit - like 500-800ms for simple queries that used to take 30ms. Turns out M10 shares CPU with every other customer, so when their analytics jobs run during lunch hours, your app becomes unusable.
Upgraded to M20 thinking it would fix the problem. Wrong. Still shared CPU, just costs more. Finally bit the bullet and went to M30. Problem solved, but now paying $400/month instead of $60.
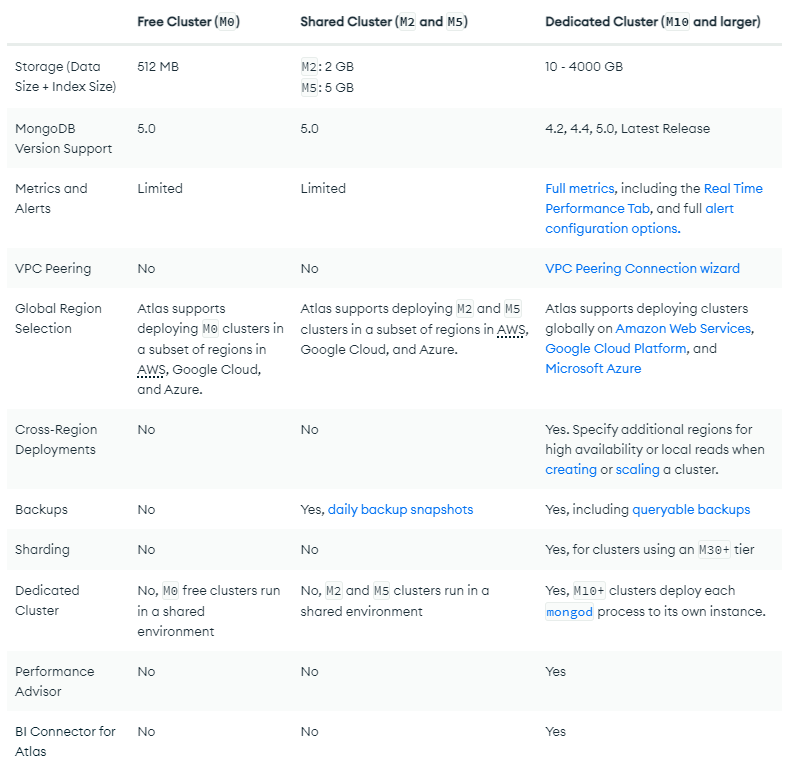
M10 is basically development only
M10 gives you 2GB RAM but only 500MB cache. My laptop has more cache than that. For any real application with indexes, you're hitting disk constantly.

Had an e-commerce client - products, users, orders, the usual. Index files alone were maybe 1.5GB. Trying to fit that in 500MB cache was hopeless. Every product search took 800ms+ because it kept hitting disk. Customer was pissed about "slow search results" daily.
Working set size will fuck you
Total data size doesn't matter. What matters is your working set - indexes plus hot data that needs to stay in cache.
MongoDB's cache allocation is stupid. M30 gets 25% cache (2GB from 8GB RAM). M40 gets 50% cache (8GB from 16GB RAM). Same money per GB, way better performance.
The MongoDB Community Forums are full of posts about M10/M20 performance issues. Atlas monitoring documentation explains how to track when you're hitting cache limits.
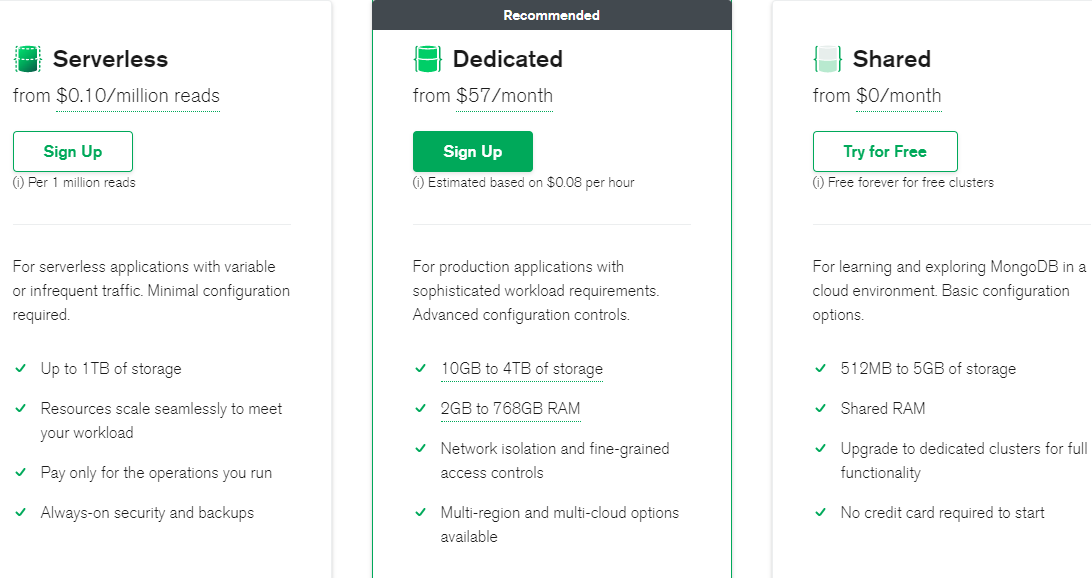
MongoDB lies about M10/M20 being production-ready
MongoDB's docs claim these work for "low-traffic production." Bullshit. They want you locked into Atlas before you realize you need to upgrade.
Every company I've worked with had the same experience - M10 works until your first busy day, then everything falls apart at 2pm when lunch traffic hits. Then you're frantically upgrading tiers while your app is dying.
M10 ($58/month):
- 2GB RAM, 500MB cache
- Shared CPU (runs like shit when neighbors get busy)
- 10GB storage (indexes eat this fast)
- 500 connections (exhausted by 2-3 services)
M20 ($146/month):
- 4GB RAM, 1GB cache
- Still shared CPU, still random performance
- 20GB storage
- 1,500 connections
Shared CPU is like shared web hosting for your database. Your 50ms queries become 300ms when some other company decides to run their daily analytics job during peak hours. You have zero control.
This is well-documented in MongoDB's cluster configuration costs page and discussed extensively in performance tuning guides. Third-party monitoring tools can help identify when shared resources are the bottleneck.
M30 is where it gets decent
M30 at $394/month finally gives you dedicated CPUs. Performance becomes predictable.
- 8GB RAM, 2GB cache
- Dedicated CPUs
- 40GB storage
- 3,000 connections
M40 at $758/month costs double but usually worth it:
- 16GB RAM, 8GB cache (4x more cache)
- 4 dedicated CPUs
- 80GB storage
- 6,000 connections
Cache difference is huge. Queries that hammer M30's 2GB cache and hit disk stay in M40's 8GB cache. Goes from 200ms to 30ms. When you're doing 50+ queries per page load, that's the difference between a 10-second page load and a 1.5-second page load.
MongoDB Atlas performance best practices and memory management guides detail how cache misses destroy performance. CloudZero's MongoDB pricing analysis breaks down the cost implications of different tier choices.
Performance Advisor will blow up your storage
Performance Advisor suggests indexes aggressively. These can double your storage and force tier upgrades.
Had a project with 7GB of data on M10. Performance Advisor suggested like 6 indexes for "faster queries." Those indexes ate 3GB of storage. Suddenly at 10GB+ and forced to upgrade to M20. Bill went from $58 to $146/month because of MongoDB's own suggestions. Felt like a scam.
Don't blindly add every suggestion. Pick 1-2 critical indexes first, see what happens.
The MongoDB indexing documentation covers index overhead in detail. Atlas billing documentation explains how storage overages force tier upgrades. Community discussions on Stack Overflow and Reddit's MongoDB community frequently address index bloat issues.
Auto-scaling will fuck your budget
Auto-scaling sounds helpful but it's a billing trap. Traffic spike for 6 hours? You pay the higher tier all month.
Startup I worked with got hit during launch day. Traffic spiked for maybe 4-6 hours. Auto-scaling bumped them from M20 to M40. Bill went from $146 to $758 for the whole month. $612 extra for a few hours of load.
Turn off auto-scaling unless you set a maximum tier limit. Otherwise it can scale infinitely and bankrupt you.
Multi-region costs 3x for no reason
Multi-region clusters multiply your cost by the number of regions. MongoDB hides this in the fine print.
- Single region M30: $394/month
- Three-region M30: $1,182/month
- Plus data transfer between regions
Most companies enable multi-region thinking they need "high availability" when 99% of users are in one area. Seen SaaS companies waste $2k/month on multi-region for mostly US users.
Start single-region. Add regions only when users actually complain about latency.
Don't optimize for cheapest tier. Optimize for the tier that won't die during traffic spikes.

