Look, I'm not going to feed you some "comprehensive enterprise AI solution analysis" bullshit. We burned through ChromaDB (nightmare), Weaviate ($$$ for garbage performance), and like 6 other combinations that demo'd perfectly but imploded the moment real users touched them. This stack is the only one that didn't make me update my LinkedIn.
The Four Tools That Actually Work Together
LangChain: Finally Stable (After Breaking Everything for 6 Months)
LangChain used to be a nightmare to work with. Every minor update broke our code. I spent more time fixing LangChain upgrades than building features. But around v0.2, they finally got their shit together.
Why it doesn't suck anymore:
- Actually works: The LCEL syntax is weird but it doesn't randomly fail
- Saves time: Native OpenAI + Pinecone + Supabase connectors mean less custom plumbing
- Has retry logic: Built-in error handling so your app doesn't crash when OpenAI has a bad day
- Debugging: LangSmith actually shows you where things break (revolutionary concept)
We tried rolling our own orchestration first because "how hard could it be?" - 3 weeks later we still couldn't stream responses without the whole thing eating RAM like Chrome with 47 tabs open. LangChain's memory management alone saved us from at least a dozen 3am "why is the server dead" pages. Yeah, it's opinionated as fuck, but after writing custom chains that leaked memory like a broken faucet, I'll take opinionated over broken.
OpenAI: Expensive But It Actually Works (Unlike Cheaper Alternatives)
OpenAI will bankrupt you if you're not careful. Our first month bill was over four grand because LangChain v0.1.15 broke our embedding caching and we re-embedded 50k documents twice. But after trying Claude (rate limits are brutal), Mistral (quality is all over the place), and various open source models (good fucking luck with deployment), OpenAI is the only one that consistently works.
Why we pay the OpenAI tax:
- Doesn't randomly break: Unlike every other LLM API we've tried (I'm looking at you, Anthropic rate limits)
- Actually has decent uptime: When they go down, everyone knows about it on Twitter within minutes
- Predictable costs: Their pricing is clear, unlike AWS bills that require a PhD to understand
- Function calling actually works: Revolutionary concept - an API that does what it says on the tin
GPT-4 Turbo's 200K context window sounds massive until you feed it a 67-page insurance PDF and watch your bill explode. text-embedding-3-large costs 12x more than ada-002 but the quality jump means I get 60% fewer "why can't I find anything" tickets from users.
Here's the shit they don't mention in their marketing: Rate limits will raw dog you without warning if you don't code exponential backoff from day one. Hit 429 errors at 3am? Good luck sleeping. And their "transparent pricing" turns real fucking opaque when you cross some magic enterprise threshold - suddenly you're on calls with sales discussing "custom tier pricing" that's 3x what the website says.
Pinecone: Expensive But Your Vectors Won't Disappear
Pinecone is pricey as hell but it actually works. We tried self-hosting Weaviate first (disaster), then ChromaDB (performance nightmare), then Qdrant (decent but requires babysitting). Pinecone just works, even when you throw 50 million vectors at it.
Why we pay the Pinecone premium:
- Actually serverless: Scales without weird capacity planning meetings
- Namespaces work: Multi-tenant isolation that doesn't leak data between customers
- Fast as shit: Sub-100ms queries even with millions of vectors
- Doesn't lose data: Unlike self-hosted solutions that mysteriously corrupt indexes
Their hybrid search improved our retrieval accuracy by like 15-20%, which translated to way fewer "your search sucks" support tickets. Worth every expensive penny.
Cold starts will absolutely ruin your morning though - hit an idle Pinecone index and wait 37 seconds for it to wake up while your user thinks the app is broken. First query of the day? Might as well go make coffee.
Supabase: PostgreSQL for People Who Don't Want to Manage PostgreSQL

Supabase is basically PostgreSQL with batteries included. After spending 6 months wrestling with Auth0 (nightmare), custom WebSocket servers (broke constantly), and raw PostgreSQL setup (killed our DevOps budget), Supabase handles all that shit for you.
Why it doesn't suck:
- Auth that works: Built-in authentication with social logins and Row Level Security that actually prevents data leaks
- Real-time without pain: Realtime subscriptions that sync document updates without custom WebSocket hell
- It's just PostgreSQL: Full SQL access, no weird NoSQL limitations
- Edge functions: Serverless compute for document processing without managing containers
pgvector support lets you store metadata in PostgreSQL while keeping high-performance vectors in Pinecone. Best of both worlds without the integration nightmare.
Their dashboard is slick until you need to migrate 500K rows with complex relationships, then you're writing raw SQL like it's 2010. But at least it's PostgreSQL, not some NoSQL bullshit that changes its query syntax every major release.
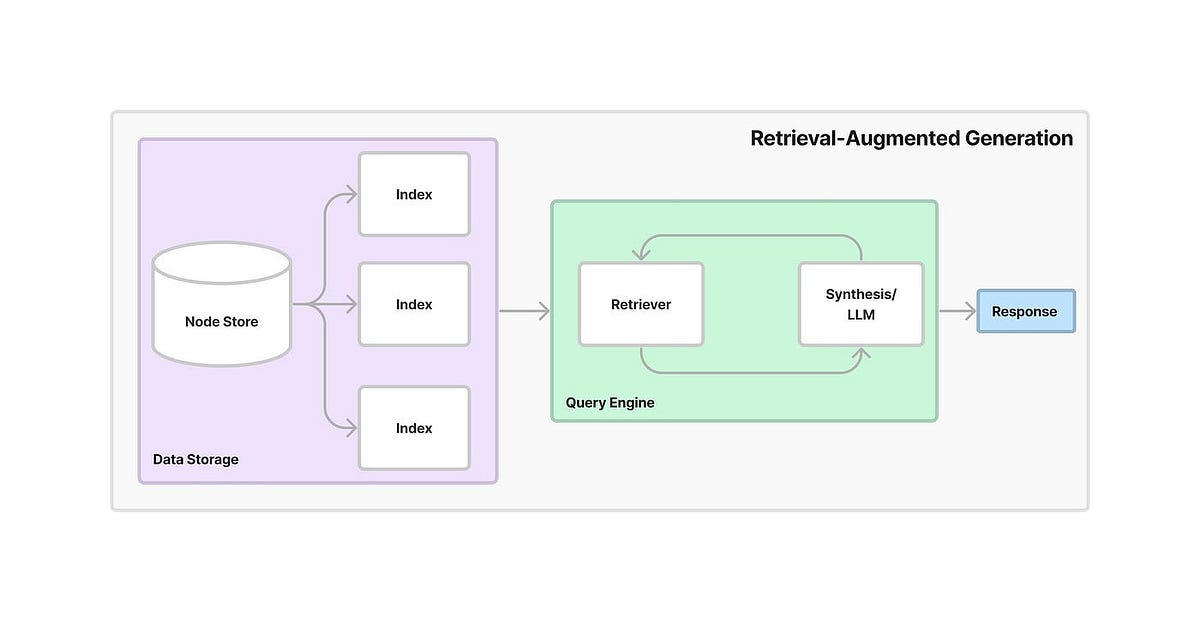
How We Actually Set This Shit Up
Multi-Tenant Vector Namespaces
Look, production RAG without proper data isolation is a compliance nightmare waiting to happen. Pinecone namespaces combined with Supabase RLS actually work for multi-tenancy:
## Namespace per organization with metadata in Supabase
namespace = f"org_{organization_id}"
vectorstore = PineconeVectorStore(
index=pinecone_index,
namespace=namespace,
embedding=openai_embeddings
)
Real-time Document Sync (That Actually Works)
Supabase realtime is one of the few real-time systems that doesn't break when you scale past demo usage:
## Real-time subscription for document changes
supabase.table('documents')\
.on('INSERT', handle_document_insert)\
.on('UPDATE', handle_document_update)\
.subscribe()
Hybrid Storage Strategy (Because Nothing Is Simple)
Store document metadata in Supabase PostgreSQL while keeping vectors in Pinecone - yeah, it's more complex but it's the only way that doesn't suck:
-- Document metadata in PostgreSQL
CREATE TABLE documents (
id UUID PRIMARY KEY,
user_id UUID REFERENCES users(id),
title TEXT,
content_type TEXT,
processing_status TEXT,
created_at TIMESTAMPTZ DEFAULT NOW()
);
-- Vector embeddings in Pinecone with document ID reference
Why This Combo Doesn't Suck (Unlike the Others)
vs. Pure OpenAI Stack: Adds real-time capabilities, user management, and cost-effective storage for metadata and chat history.
vs. Open Source Stack: Eliminates operational complexity while maintaining flexibility. No Kubernetes clusters to manage, no vector database tuning, no custom auth implementation.
vs. All-in-One Platforms: Preserves architectural control and prevents vendor lock-in. Each component can be replaced or scaled independently.
This combo actually stays up and doesn't randomly die. We went from constant fire drills to maybe one actual outage in the past 6 months. Query times hover around 400-800ms unless you're doing something stupid like not implementing caching - though sometimes it spikes to like 2 seconds when Pinecone decides to be slow.
We've seen this working at tiny startups and massive companies. Handles crazy loads without falling over, which is more than I can say for the previous 3 stacks we tried. Though I think we got lucky with our usage patterns - your mileage may vary.