After Jenkins pipelines died randomly and GitLab CI murdered our AWS bill, we finally got a GitOps setup that works. Took six months, three postmortems, and one very awkward all-hands about why checkout was fucked for two hours on Black Friday.
GitOps Finally Solved Our "Who the Hell Deployed This?" Problem
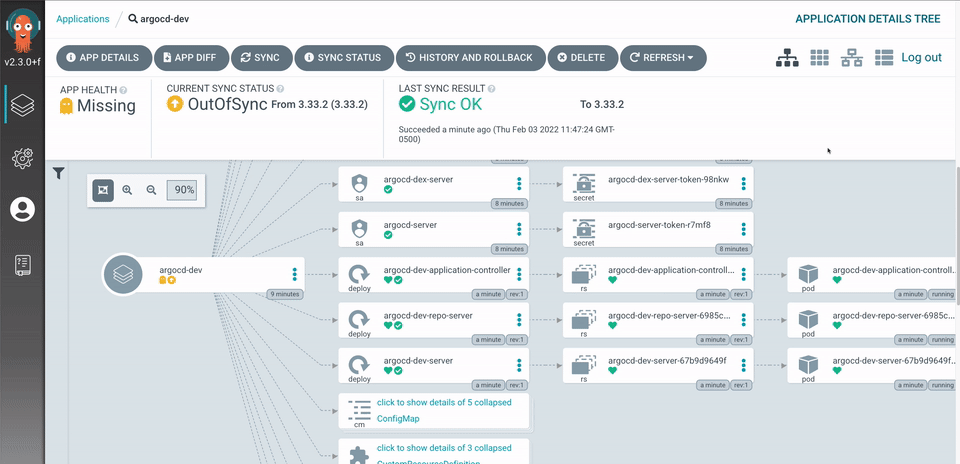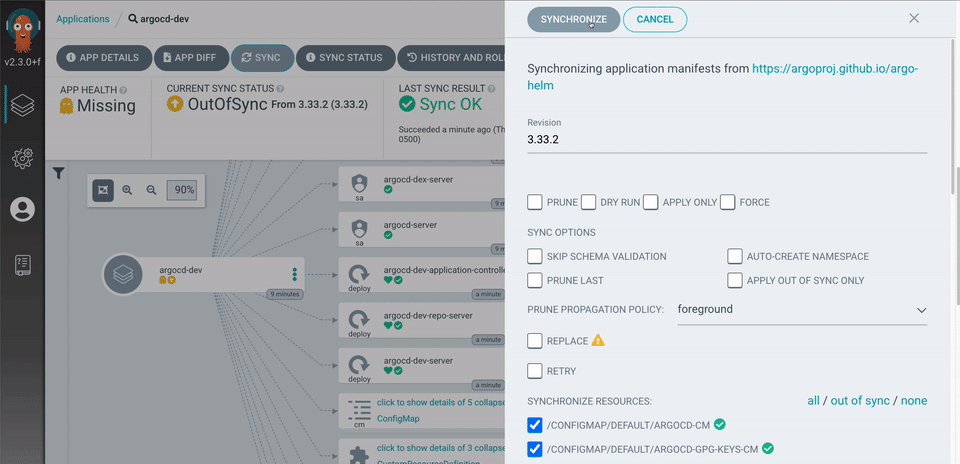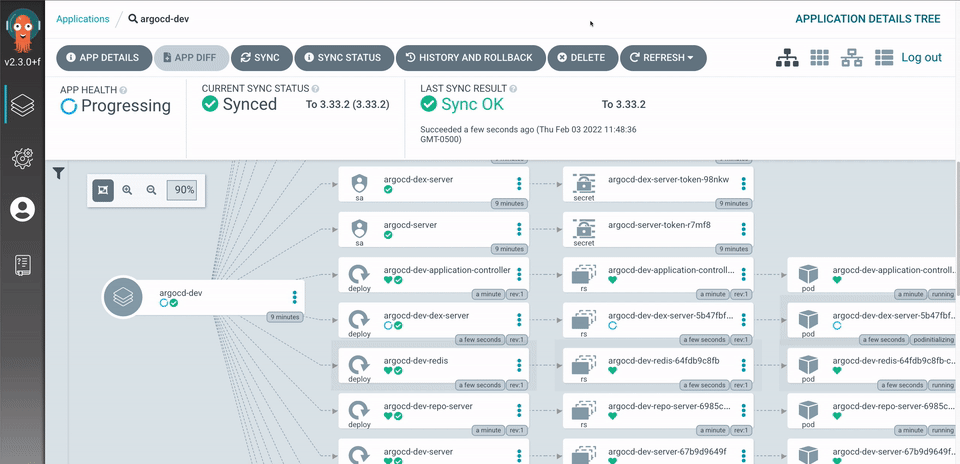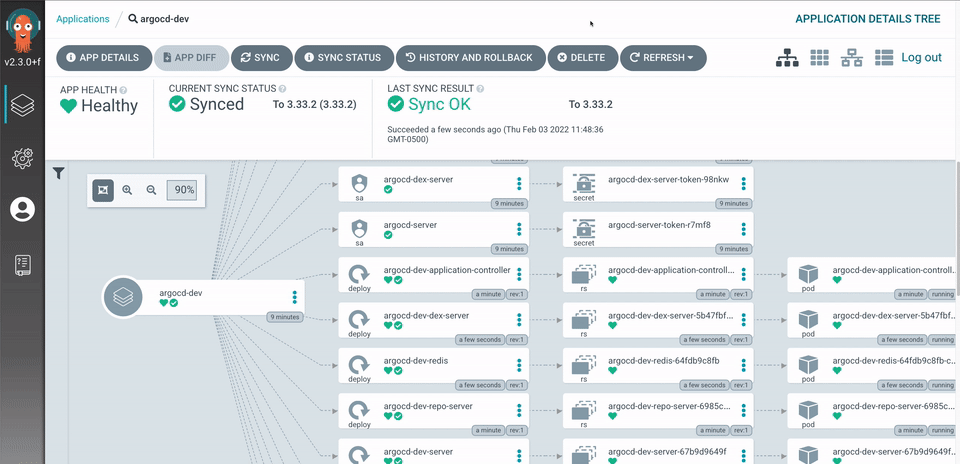
Here's the thing about traditional push-based CI/CD: when shit hits the fan at 3 AM, you're frantically digging through Jenkins logs trying to figure out what got deployed when. With GitOps, every deployment is a Git commit. Need to rollback? git revert. Need to audit who deployed what? git log. When ArgoCD pulls from Git instead of Jenkins pushing random builds, you actually know what's running in production.
The first time our on-call rotation went from weekly pages to maybe one alert in a month, we knew we were onto something. Turns out most outages happen because someone deployed something and forgot to tell anyone.
The Two-Part System That Stopped Our Weekend Debugging Sessions
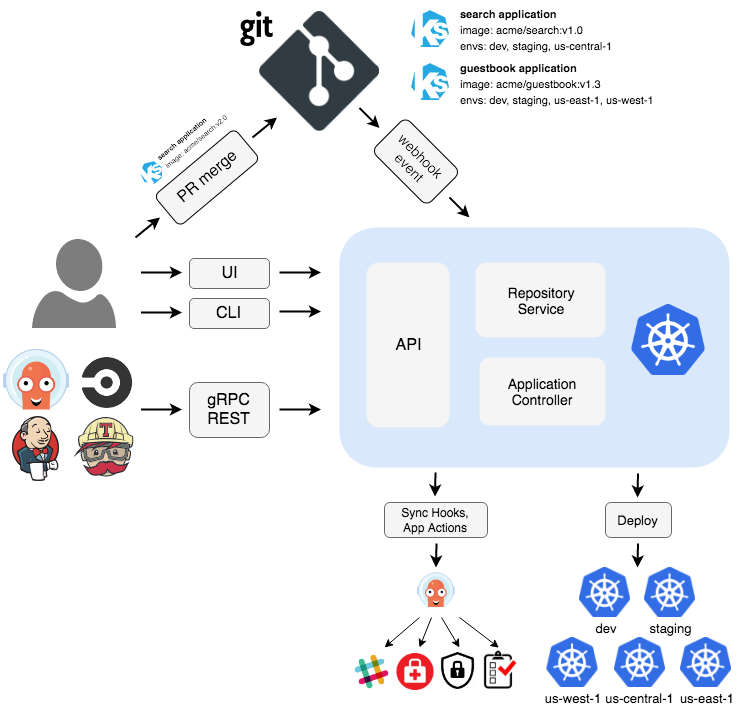
Here's how it works when it's not breaking:
GitHub Actions handles the build stuff (this part usually works):
- Developer pushes code, Actions runs tests and security scans
- If tests pass, builds Docker image and shoves it into the registry
- Updates the deployment manifest with the new image SHA (not tag - learned this the hard way)
ArgoCD handles the deployment nightmare (this is where things get interesting):
- ArgoCD obsessively watches your Git repo for changes every 3 minutes
- Spots the new manifest, syncs it to your cluster
- Rolling deployment happens with health checks (when they're configured right)
- If your app dies during deploy, ArgoCD automatically rolls back
I learned about the separation after our monolithic Jenkins setup ate itself during a deploy and took both CI and CD down. Two systems means when one shits the bed, the other keeps working. Google's SRE book calls this "blast radius reduction" - we called it "thank god we can still deploy hotfixes."
What You Need Before Starting (Don't Skip This Shit)
Seriously, don't start unless you have:
- Kubernetes cluster (k3d works for learning, but you'll need EKS/GKE for anything real)
- GitHub repo with admin rights (you'll need to add secrets and webhooks)
- Container registry (Docker Hub rate limits will bite you, use ECR/GCR)
- Domain + SSL cert (Let's Encrypt is fine, just don't use self-signed certs)
- You've used kubectl before and know pods from deployments
This took me an entire weekend, and I thought I knew what I was doing. If you're new to this shit, clear your schedule for the next month. Those "5 minute setup" guides are fucking lies written by people who've never seen production.
The Modern Stack We're Using
GitHub Actions handles CI because:
- Native GitHub integration with zero configuration
- Powerful workflow syntax that scales from simple to complex
- Massive ecosystem of pre-built actions
- Built-in secret management and OIDC authentication
- Matrix builds for testing across multiple environments
- Artifact storage and caching built-in
ArgoCD handles CD because:
- Kubernetes-native GitOps with proper RBAC integration
- Visual deployment tracking and rollback capabilities
- Multi-cluster management for staging and production
- Progressive delivery with Argo Rollouts
- Active development and strong CNCF backing
- SSO integration with LDAP, OIDC, SAML
Helm manages Kubernetes manifests because:
- Templating reduces duplication across environments
- Version control for infrastructure configuration
- Easy rollback to previous chart versions
- Industry standard for Kubernetes application packaging
- Values file override for environment-specific config
- Dependency management for complex applications
Real-World Production Considerations
Here's the shit nobody tells you about production:
Security: Every component needs proper authentication. GitHub Actions uses OIDC to connect to cloud providers without storing long-lived credentials. ArgoCD uses Kubernetes RBAC to limit what it can deploy. Implement network policies, pod security standards, and image scanning.
Monitoring: You need observability into every step. GitHub Actions provides build metrics, ArgoCD shows deployment status, Kubernetes gives runtime metrics. Set up AlertManager for failed deployments, not just successful ones.
Compliance: Git history becomes your audit trail. Every production change must go through this pipeline - no manual kubectl commands. GitOps provides complete change traceability which SOC2 and ISO27001 auditors require.
Disaster Recovery: Your entire infrastructure is in Git. If your cluster dies, you can recreate it exactly by applying your Git repository. This is infrastructure as code taken to its logical conclusion.
What Success Looks Like
When properly implemented, this pipeline gives you:
- Sub-10-minute deployments from commit to production
- Automatic rollback on deployment failure
- Complete deployment history in Git
- Visual deployment tracking in ArgoCD UI
- Zero-downtime deployments with proper health checks
- Multi-environment promotion from dev to staging to production
Management loves metrics, so here's what we saw after switching (your mileage will definitely vary):
- Deployment frequency: Multiple times per day
- Lead time: Less than 1 hour from commit to production
- Change failure rate: Less than 5%
- Recovery time: Less than 1 hour
Common Anti-Patterns to Avoid
Don't put application code and deployment manifests in the same repository. Separate repositories prevent deployment changes from triggering unnecessary application builds.
Don't use ArgoCD for CI tasks like building images or running tests. ArgoCD is for deployment only. Separation of concerns applies to CI/CD tooling too.
Don't manually edit cluster resources after deployment. Everything must go through Git. Manual changes create configuration drift that breaks future deployments.
Don't store secrets in Git repositories, even if they're encrypted. Use Kubernetes secrets managed by external secret operators like External Secrets Operator or Sealed Secrets.
Alright, enough theory. Time to build this thing. Next up: GitHub Actions that won't randomly die when you need them most.