Most tutorials show you how to send a "Hello World" message and call it event-driven architecture. That's like showing someone console.log() and claiming they know JavaScript.
I've spent 4 years dealing with event systems that process anywhere from 10K to 500K messages per second. Here's what actually happens when you build this stuff for real.
Martin Fowler's event-driven guide actually covers the real-world stuff unlike most academic bullshit.
The Reality Check: What Event-Driven Actually Means
Event-driven architecture (EDA) means your services communicate by publishing events about what happened and consuming events to react to changes. But here's what separates production systems from playground demos:
Stuff that actually matters when you're getting paged at 3am:
- Messages don't just vanish when a container restarts (way harder than it sounds, learned this the hard way)
- Consumer lag doesn't spiral out of control during traffic spikes (hit 6+ hours once, was not fun)
- Dead letter queues exist and someone actually fucking monitors them
- Schema changes don't break every downstream service (one field removal broke 8 services once)
- You can replay events without the entire system shitting itself
- Circuit breakers actually work instead of making everything worse (ours opened all at once once, still don't know why)
Why Traditional Request-Response Breaks at Scale
Synchronous REST APIs between microservices create a house of cards. When your payment service calls the inventory service, which calls the shipping service, which calls the notification service, you've created a distributed monolith with single points of failure everywhere.
The synchronous failure cascade:
Order API → Payment Service → Inventory Service → Shipping Service
↓ ↓ ↓ ↓
200ms timeout 503 error service down
Result: A failed inventory check brings down your entire order flow. We learned this the hard way when a single Redis timeout cascaded through 8 services and killed our entire checkout process for 45 minutes during peak traffic.
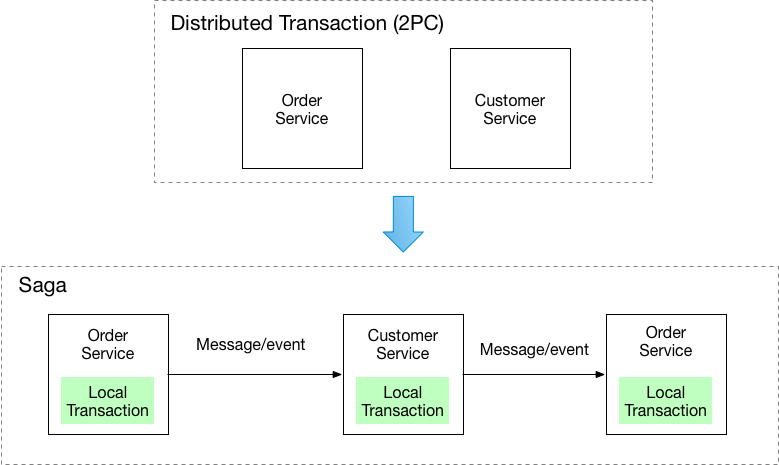
Event Patterns That Actually Work (And The Ones That Don't)

Here's what actually works when shit hits the fan. There are 3 patterns that work, maybe 4 if you count the weird hybrid approach we tried.
1. Event Notification Pattern
Services emit lightweight events about state changes. Other services decide what to do with those notifications.
{
"eventType": "OrderPlaced",
"orderId": "ord_12345",
"customerId": "cust_67890",
"timestamp": "2025-09-09T14:30:00Z",
"amount": 299.99
// TODO: add correlation ID, this shit is hard to debug without it
}
When to use: Real-time notifications, analytics pipelines, audit logging.
2. Event-Carried State Transfer
Events contain complete state information, reducing the need for additional API calls.
{
"eventType": "CustomerProfileUpdated",
"customerId": "cust_67890",
"profile": {
"name": "Jane Smith",
"email": "jane@example.com",
"tier": "premium",
"preferences": {...}
},
"version": 5,
"timestamp": "2025-09-09T14:30:00Z"
}
When to use: When downstream services need complete context, reducing API chattiness.
3. Event Sourcing Pattern
Store events as the source of truth, derive current state by replaying events.
// Event store
const events = [
{ type: "AccountCreated", amount: 0, timestamp: "2025-01-01" },
{ type: "MoneyDeposited", amount: 1000, timestamp: "2025-01-02" },
{ type: "MoneyWithdrawn", amount: 200, timestamp: "2025-01-03" }
];
// Current balance = replay all events
const currentBalance = events.reduce((balance, event) => {
switch(event.type) {
case "MoneyDeposited": return balance + event.amount;
case "MoneyWithdrawn": return balance - event.amount;
default: return balance;
}
}, 0); // Result: 800
When to use: Auditing requirements, complex business logic, need for temporal queries.
Message Broker Selection: The 2025 Landscape
![]()
After 4 years of running different brokers in production, here's what I've learned:
Kafka: The 800-pound gorilla that everyone uses. Handles serious throughput but you'll need someone who actually understands JVM tuning (good luck finding them). Expect to spend weekends debugging consumer rebalancing bullshit. Kafka 3.6.0 broke our consumers with a COORDINATOR_NOT_AVAILABLE error that took 8 hours to fix. I fucking hate managing Kafka, but it works.
NATS: Way simpler to operate than Kafka, which is refreshing. Good performance, smaller memory footprint. The catch? Way smaller ecosystem and fewer tools when shit breaks at 2am.
Pulsar: Tried this for 2 weeks, went back to Kafka. It's like Kafka with better multi-tenancy but more complex to operate. The community is tiny compared to Kafka's.

Redis Streams: Perfect for simple use cases and prototyping. Just don't expect durability guarantees - our Redis crashed once and we lost 3 hours of events.
How to Not Fuck This Up: Implementation Strategy
Don't be the team that implements event sourcing, CQRS, and saga patterns all at once and then spends 6 months debugging why nothing works. I've seen this pattern kill three different projects.
Start small or you'll hate your life. I began with user registration events because they're simple and won't take down payments if I fucked up. Get monitoring set up first - you'll need it when things break at 2am. Learn to hate consumer lag before you scale, trust me on this.
Then add a few more event types once you're not completely terrified. We added order events and payment events next. Watch your dead letter queues fill up with garbage you didn't expect. Implement schema versioning before you need it - learned this the hard way when one field change broke 15 services.
Finally, move to the advanced stuff only when you're comfortable with the basics. Event sourcing for the domain that actually needs it (billing for us). Saga patterns - prepare for debugging hell, I'm not kidding. CQRS if you really need read/write separation (spoiler: you probably don't).
Most teams skip the simple stuff and wonder why their event system is unreliable. Don't be those teams - I was one of those teams.
Next up: the actual implementation details and all the ways it breaks in production.